

The Prod Stack
for AI Audio
Speechbase is the foundation for AI teams to build faster with generative audio. Speech Gateway, Observability, Pronunciations, and Voice Management, all in one platform.
End-to-end Audio Orchestration and Provider Management
One API to connect your app to every TTS provider.
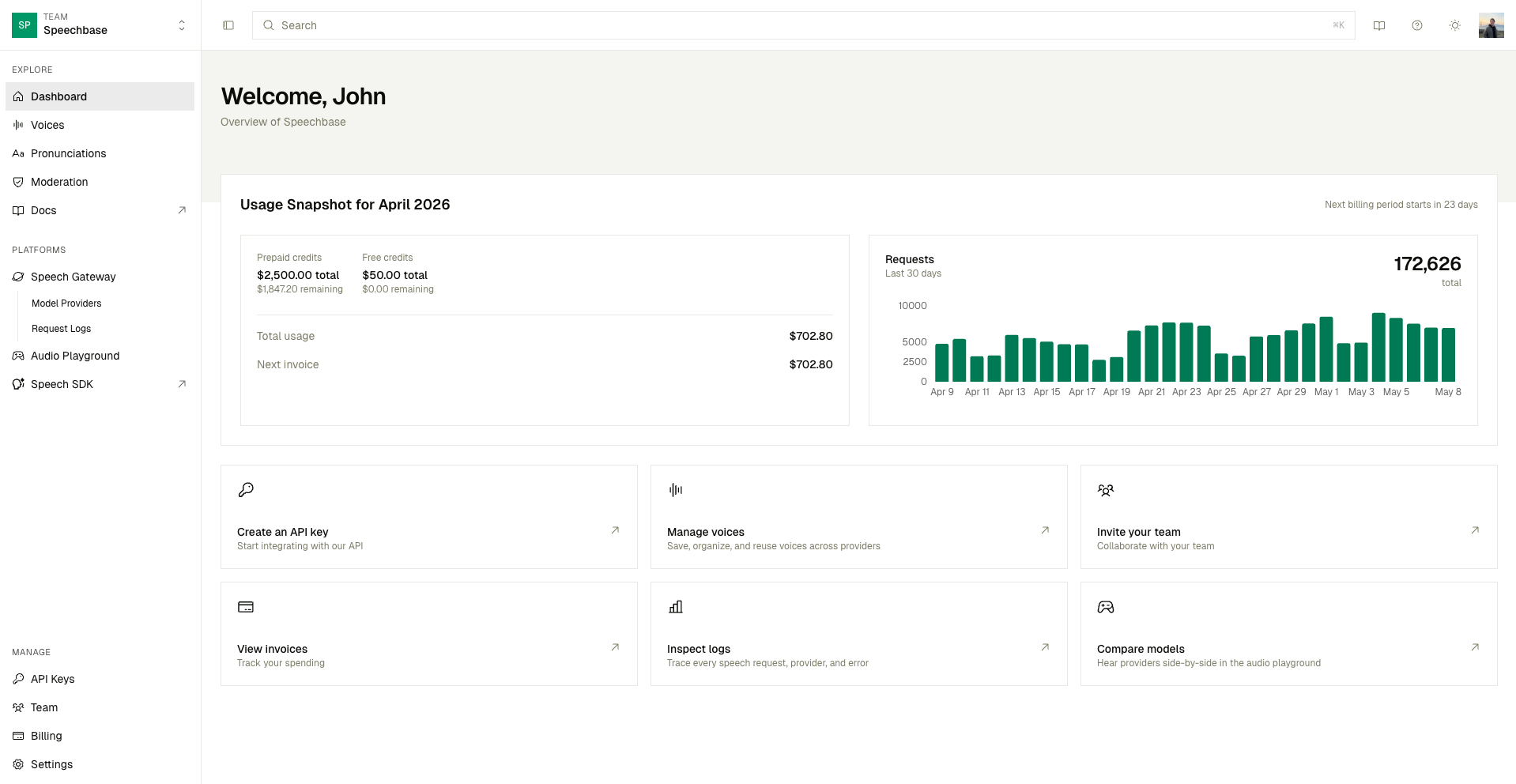
Speechbase gives AI teams a single, universal API across 16 text-to-speech providers, plus the observability, voice tooling, and governance that applications running in production actually need.
The foundation of a production audio stack.
06 primitivesA single voice library across multiple platforms.
Save voices once, reference them by name, and reuse them across providers and models. No more juggling opaque voice IDs across 16 dashboards.
- Cross-provider voice library
- Preview voices in the playground
- Reference voices globally by alias or ID
- Create voice clones (coming soon)
Open SDK. No lock-in.
Swap providers with a string change. Apache 2.0, runs anywhere, and pairs with the hosted Speech Gateway, Observability, Pronunciations, and Voice Management when production catches up.
import { generateConversation } from "@speech-sdk/core";
const result = await generateConversation({
turns: [
{
model: "elevenlabs/eleven_v3",
voice: "EXAVITQu4vr4xnSDxMaL",
text: "Hello from the SDK.",
},
{
model: "google/gemini-3.1-flash-tts-preview",
voice: "Kore",
text: "One call. Multiple voices. Auto-leveled.",
},
],
});
result.audio.uint8Array; // Uint8Array
result.audio.mediaType; // "audio/mpeg"One call returns the full multi-turn script as a single volume-leveled file. Mix providers per turn, get per-turn timestamps, skip the stitching code.
Audio streams as it generates via a standard Web ReadableStream. Pipe straight into a Response for low-latency playback in Node, Edge, or browser.
Write [laugh] once. The SDK passes through, translates to SSML, or strips with a warning. Same syntax across every provider.
Pitch-preserving WSOLA time-stretch on mono PCM. Timestamps and audioDurationMs auto-scale by 1/speed so timings stay accurate.
Long inputs split on balanced sentence boundaries (ASCII, CJK, Devanagari, Arabic) and stitch into one file, balanced so prosody stays continuous.
Jittered backoff on 5xx + 429. Retry-After honored. RFC 7807 errors with stable codes. Retry logic stays a one-liner.
Promote your speech stack to production.
10 million free characters a month. Every TTS provider. No credit card to start.